The Wrong Target
The comma video compression challenge looked like a video codec contest.
The scoring rule made it something stranger.
A submission inflates an archive back into video frames. The score is bitrate plus distortion. In this challenge, distortion means model-output drift.
The frames go through two frozen neural networks, PoseNet and SegNet. The score compares their outputs to the outputs on the original video.
The target became evaluator fidelity.
That was the first trap. If you try to make the video look good, you can spend bytes on things the evaluator ignores.
Autoresearch
This took more than one clever idea. I ran an autoresearch loop.
The loop was boring on purpose:
form a hypothesis
build the smallest test
run the official metric
write down what happened
kill it or keep going
This produced a lot of failures:
- latent side channels
- renderer changes
- postprocess controls
- learned representations
- low-resolution video paths
- mask perturbations
Some of these looked good on eight samples and then fell apart on the full 600.
The useful artifact was the negative cache: a list of dead ends with enough numbers attached that we could stop revisiting them.
That mattered because the benchmark had traps.
A candidate could look plausible and score badly. A tweak could improve PoseNet and hurt SegNet. A method could pass a small subset and regress on the full evaluator. A few extra kilobytes could erase a real gain.
Only the final score counted.
Where Are the Bytes Going?
After enough failed branches, the search stopped asking:
How do we make the generated video better?
It started asking:
Where are the bytes going?
The best baseline we had already stored a semantic mask, a small pose stream, and a tiny neural renderer. At inflate time, the renderer generated frame pairs from those side channels.
That was the right shape for this metric. PoseNet and SegNet cared about pose, segmentation, and enough surrounding texture to keep their outputs stable.
The semantic mask still lived inside an AV1 grayscale video.
That was practical, and still the wrong abstraction.
The Mask Tensor
The inflater needed exact class IDs:
- five classes
- 600 frames
- one class ID per pixel
Five classes over 600 frames is a tensor.
So the branch that mattered was a custom mask codec.
We encoded the rounded semantic mask directly with a range coder. Each pixel was predicted from nearby pixels and the previous frame. The renderer got the same class tensor as before. The archive stopped paying for a video codec's version of it.
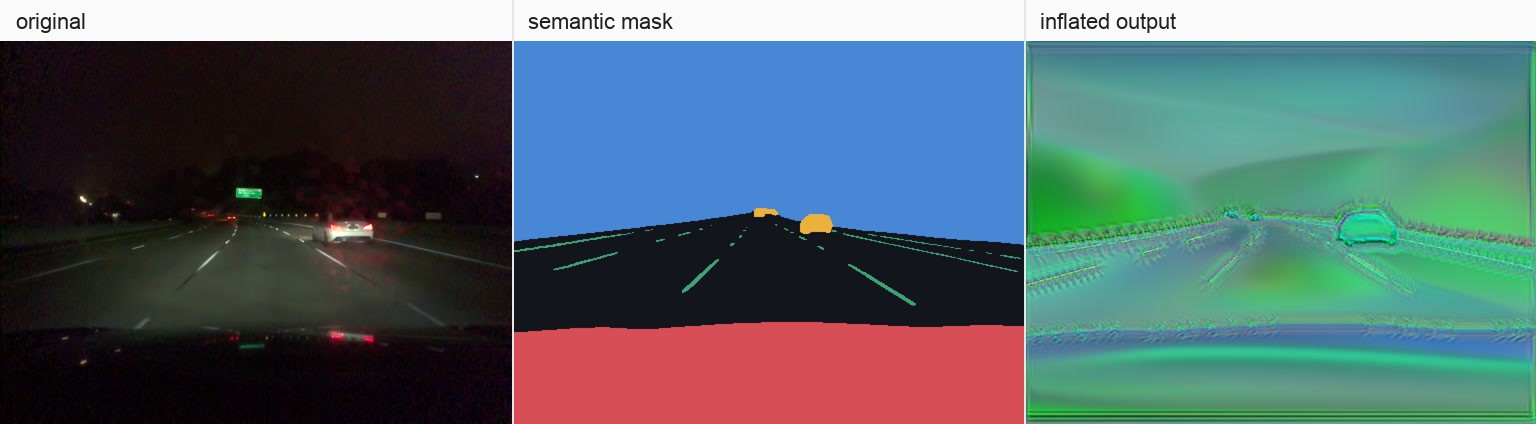
A single frame through the submission path: original frame, decoded mask tensor, inflated output.
This is what the result looked like. Original on the left. Inflated submission on the right.
The generated video preserves the signals the metric reads.
What Shipped
The rest was byte work.
We split the model payload into streams that compressed better. We quantized the pose side channel. We added a tiny per-pair router for deterministic postprocess tweaks. Then we packed everything into one archive member.
The final archive member broke down like this:
- range-coded mask: 159,011 bytes
- split renderer payload: 55,725 bytes
- quantized pose stream: 899 bytes
- router actions: 225 bytes
- zip overhead: 100 bytes
Inflation skips the original video and the evaluator networks. It decodes the archive, rebuilds the mask and generator, renders frames, and writes raw video.
The final submission, qzs3 range mask, was 215,960 bytes and got a visible score of 0.28.
I think of it as a small generator built for two neural networks.
The agent helped because it kept doing the boring part: try something, measure it, write it down, keep going.
My job was to keep asking whether the search was pointed at the real bottleneck.